We scraped a few reports related to Fintech and collated key terms that are associated with Fintech. We also scraped jobs from two of the assigned largest banks in the US and evaluated hiring trends in these banks. We build a dataset with features that can be used to analyze hiring trends in Fintech in the 24 largest banks by market cap in the United States.
In this assignments we have done:
1. Aggregation of multiple datasets into a single dataset.
2. Build a list of 100 keywords in Fintech and assign Fintech categories to each keyword and then find out if a job is related to the fintech or not.
3. Assign the categories as features to each job posting if it is a fintech related job
4. Pipeline the all tasks in to luigi application and dockerize it.
1.Forming clusters(categories) for different areas in fintech
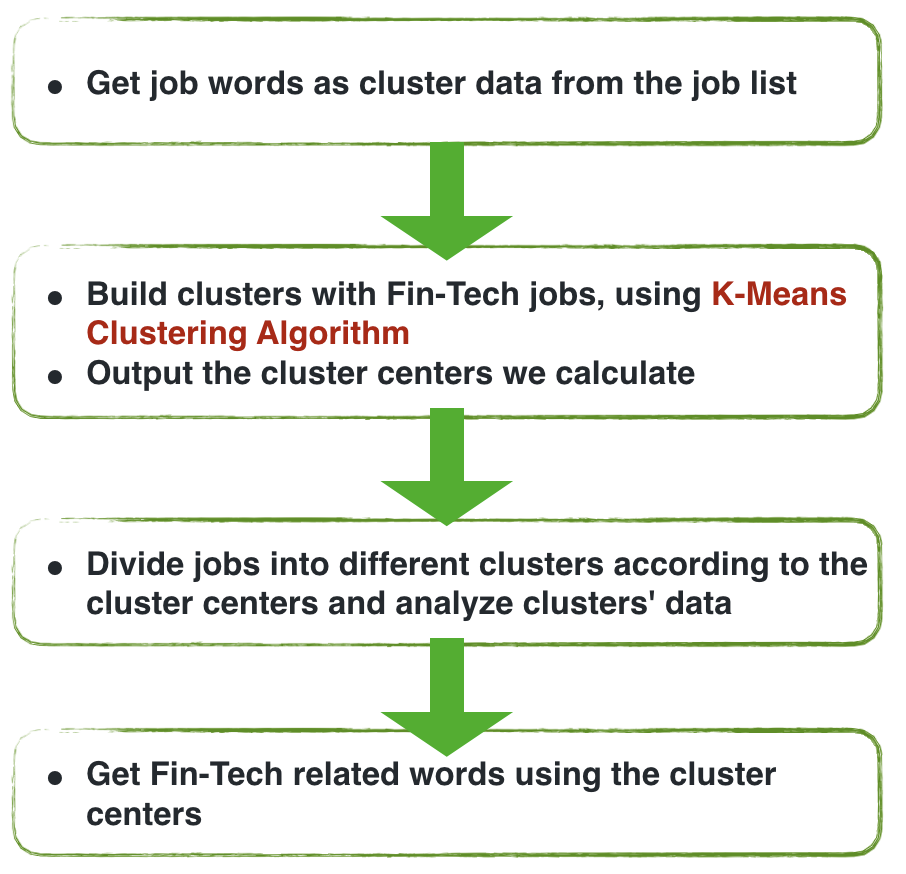
2.Feature Engineering

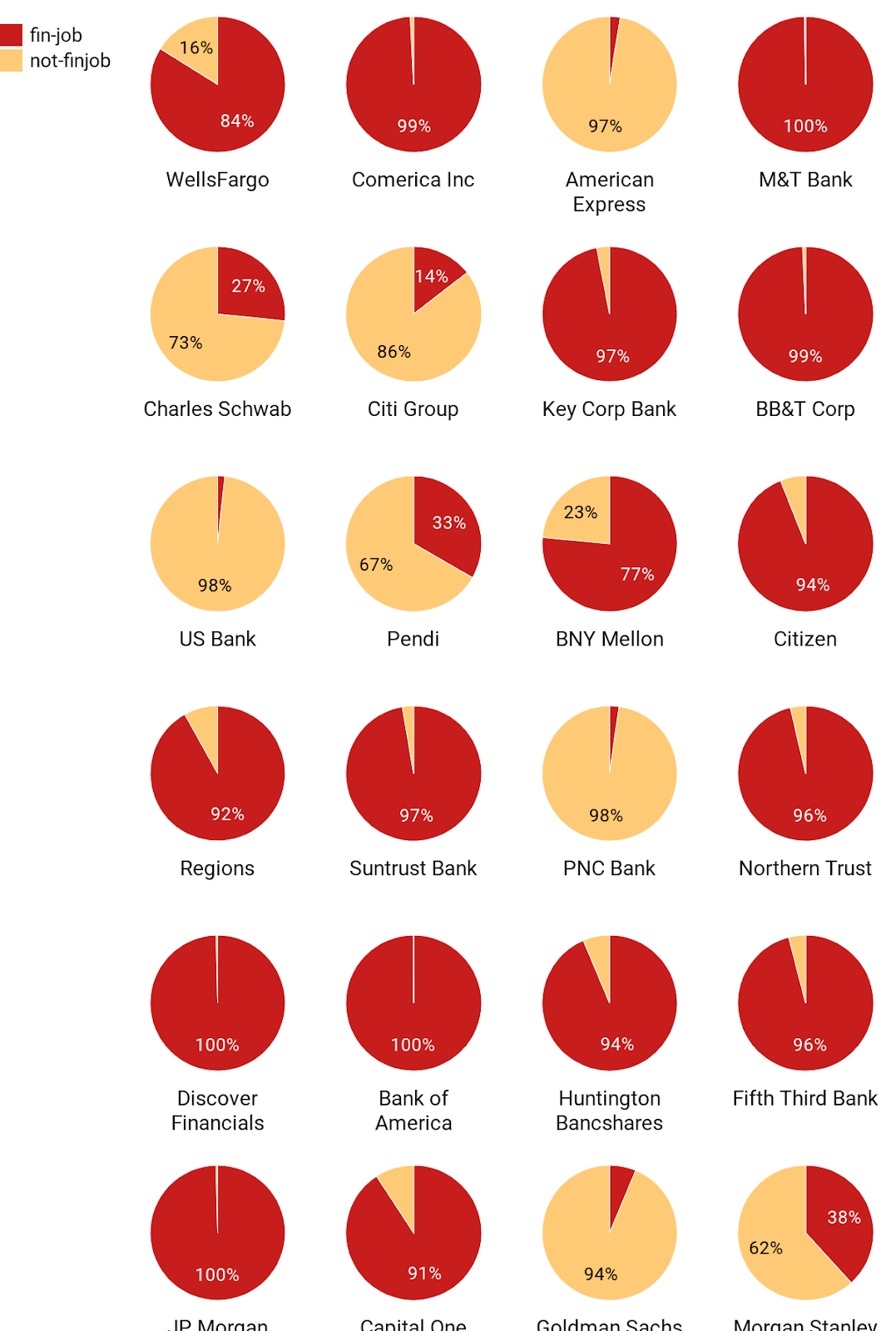
1.How are the top 24 banks hiring?
As you can see in these top 24 banks, there are 16 banks which include larger proportion of jobs in Fin-Tech Area than other normal jobs. And among these 16 banks, there are 2 banks' fintech job ratio is between 70%~80%, 16 banks' are above 90%, and includes 4 banks(M&T Bank, Discover Financials, JP Morgan, Capital One) which ratio is 100%.
2.How are the fintech related job hiring trends?
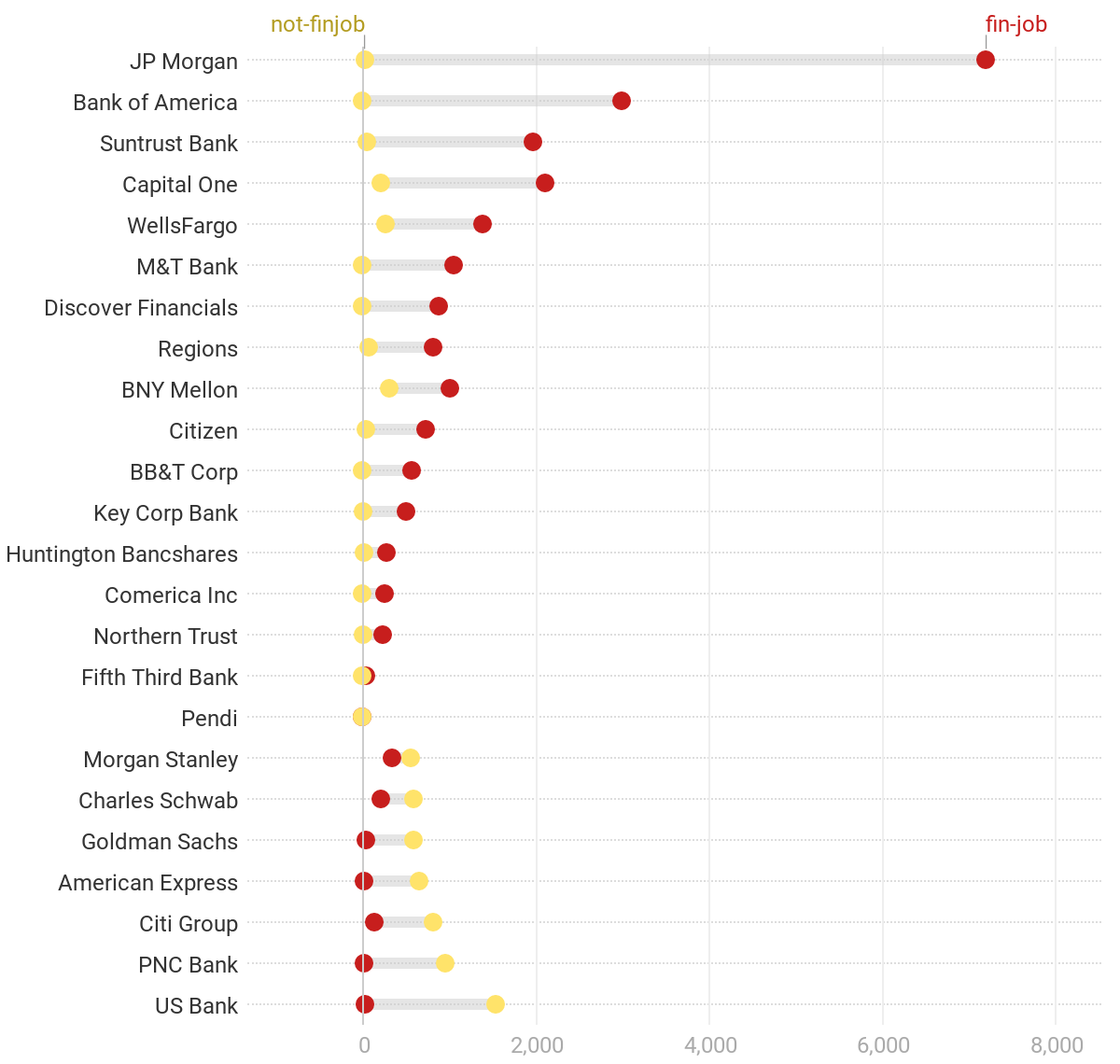
Obviously, most big successful companies have more fintech related jobs than the small-scale companies.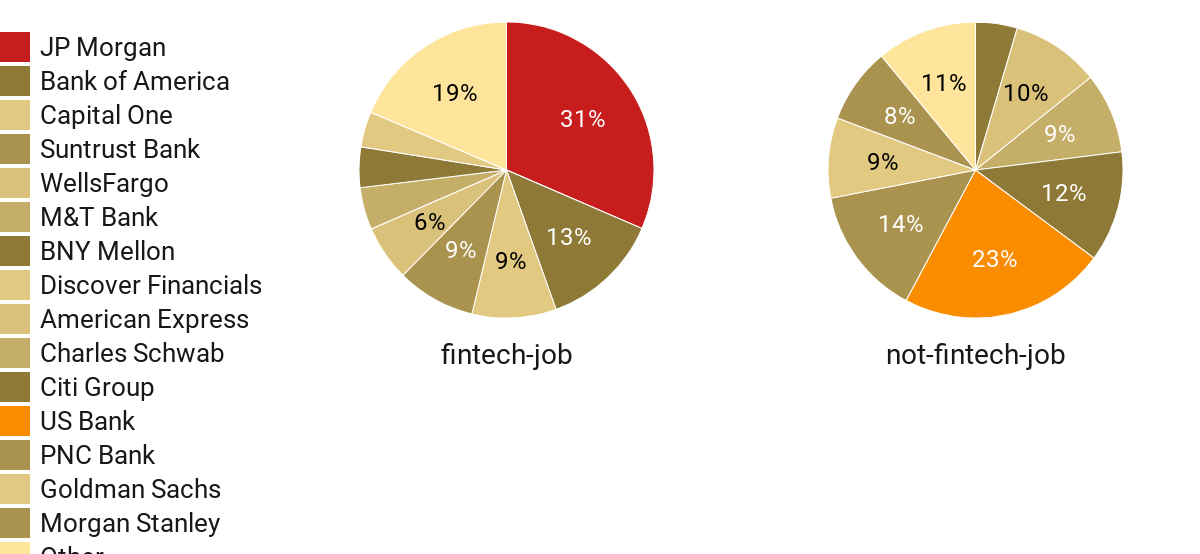
According to this graph, we can see there are huge requirements of Fin-Tech related jobs.
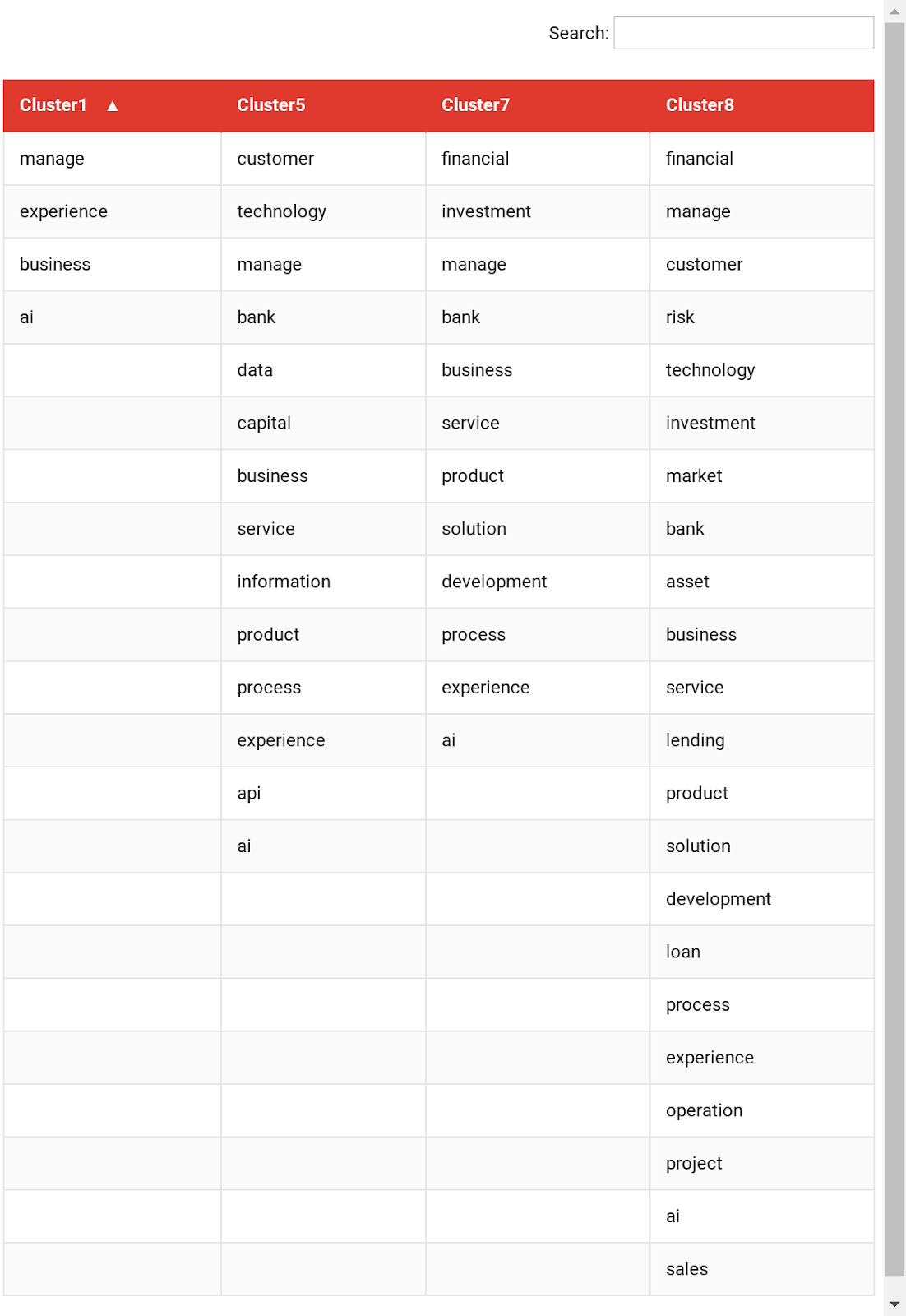
According to this graph, we obtained the job keywords in the four areas of fintech. Then we cross check job title of every records from the raw data.
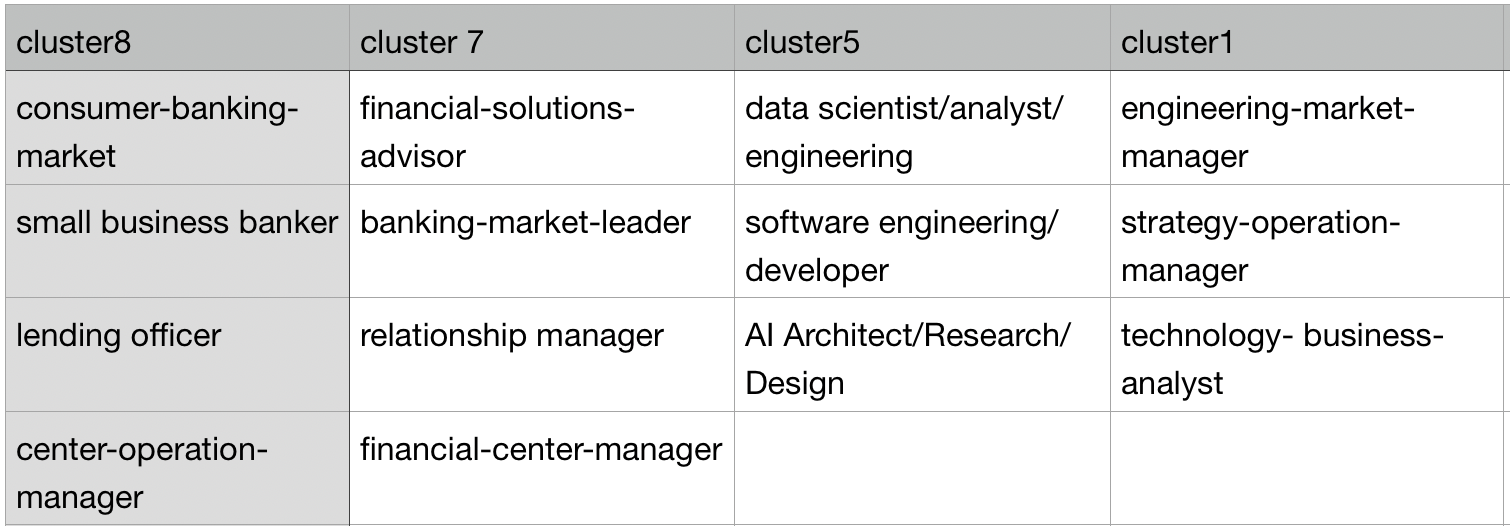
Finally we get the most related job titles of each cluster.
3.Which companies have the most fintech related jobs and which ones least?
JP Morgan has the most fintech related jobs and Pendi has the least fintech related jobs.
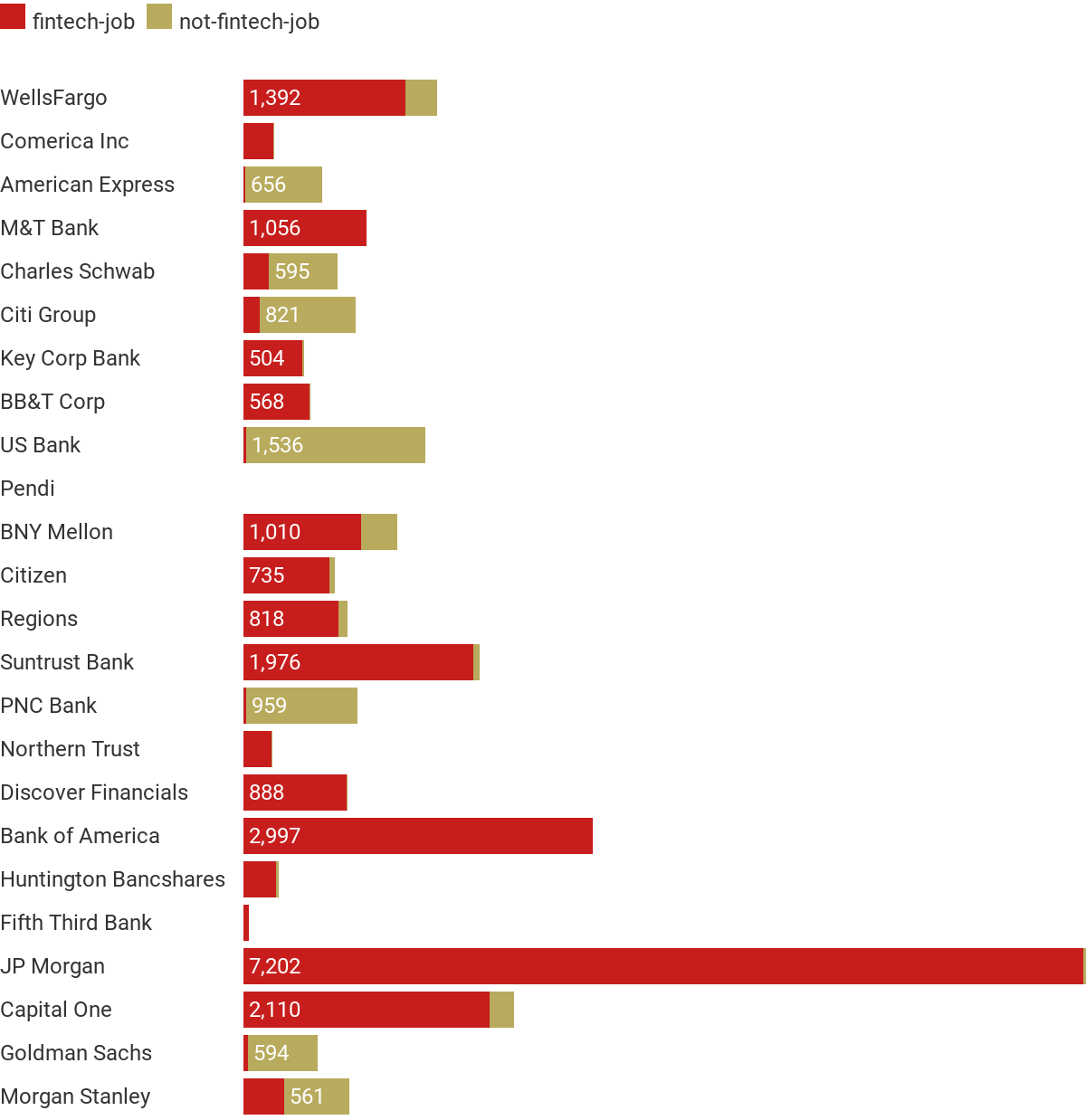
4.Rank the jobs in fintech categories.
Cluster 1 have the most fintech related jobs.
Rank 1.Cluster 1
Rank 2.Cluster 7
Rank 3.Cluster 8
Rank 4.Cluster 5
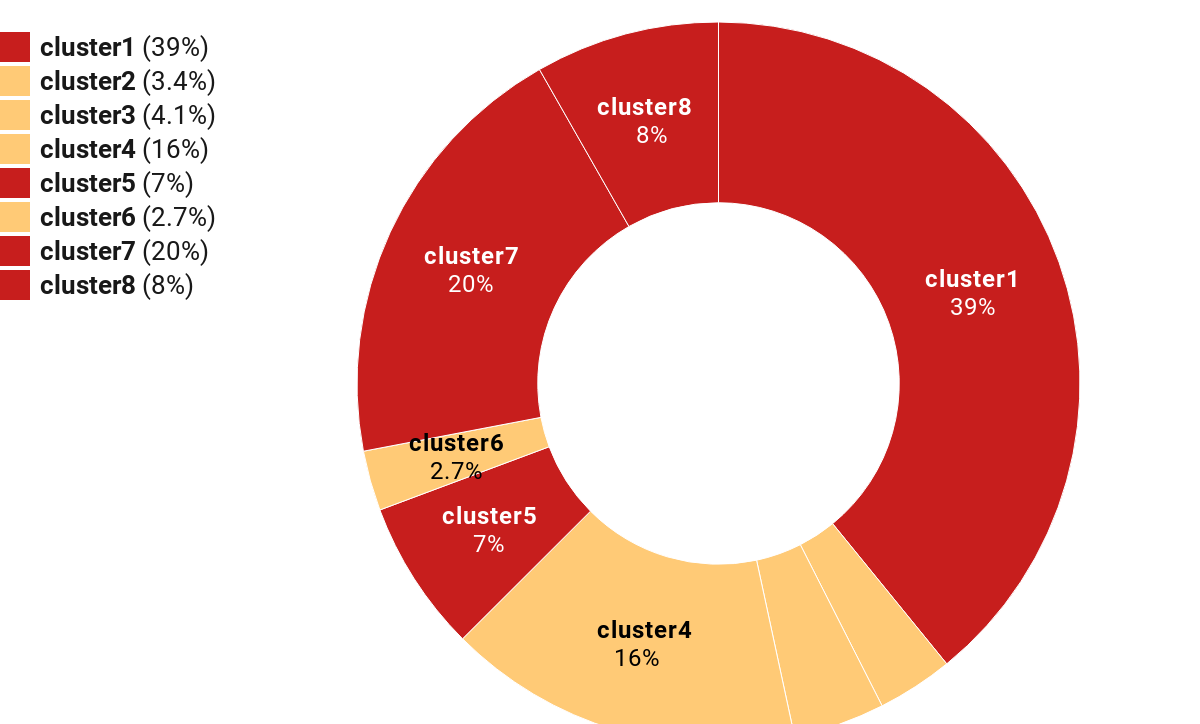
5.Which categories have the most jobs and which ones least?
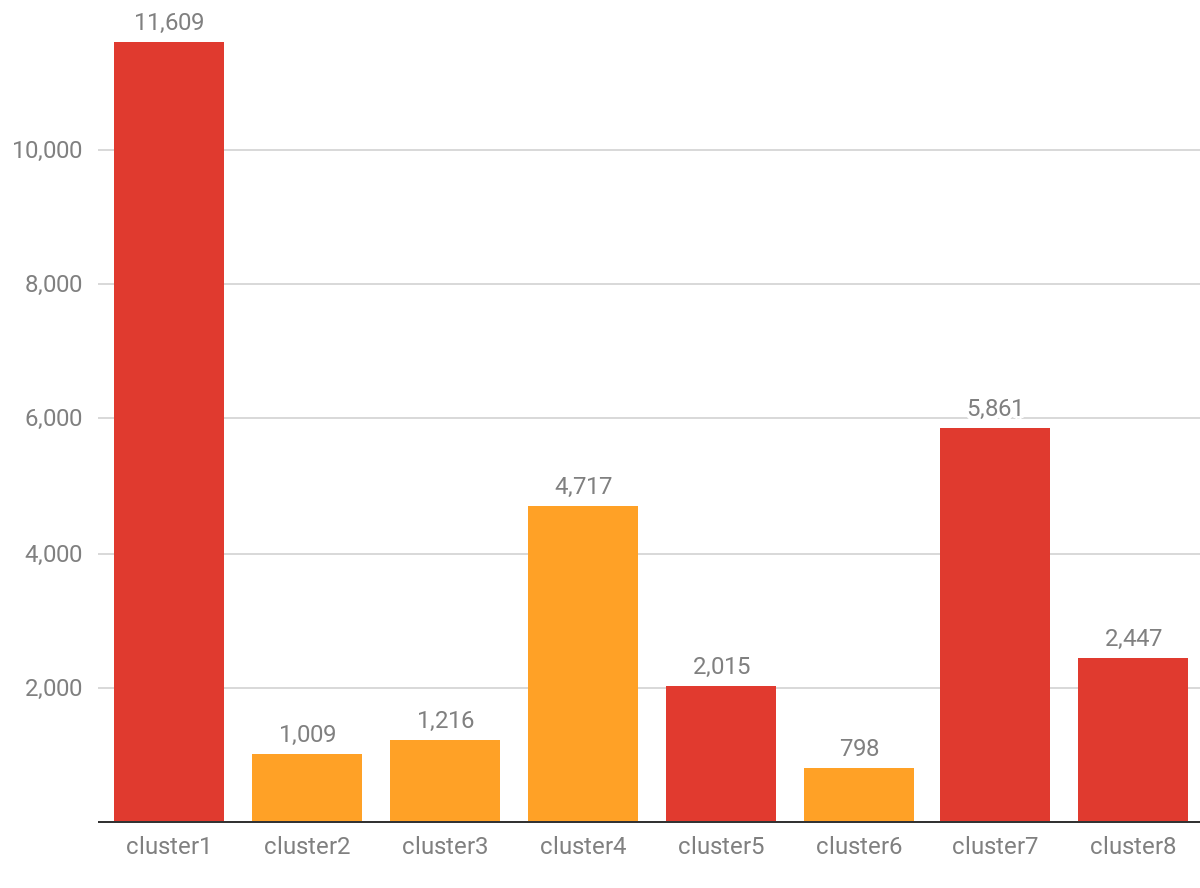
Cluster 1 has the most jobs and cluster 6 has the least jobs.
6.If you have a job seeker, which areas would you recommend the job seeker to focus on based on available jobs?
According to the above form, we can give the suggestion from each cluster. For example from cluster 7, we strongly recommend the job seeker to find the job like financial-solution-advisor. And in cluster 1, we can tell him to find the job that is related to the engineering-market-manager or technology-business-analyst.
1.Using Luigi to Pipeline Tasks
There are two main tasks in Part 3 of this assignment. One is to get the fintech file and determine if the job is related to the fintech or not. Second is to assign each job to fintech category using regression algorithm. The output of the step 1 is the input of the step 2. So we can build a pipeline by rewriting the code of part 3, so we can combine the two steps together and run them automatically. The final program should run through terminal command line: PYTHONPATH='.' luigi --module (file_name) (task_name). The result of the running is visible on the localhost:8082.
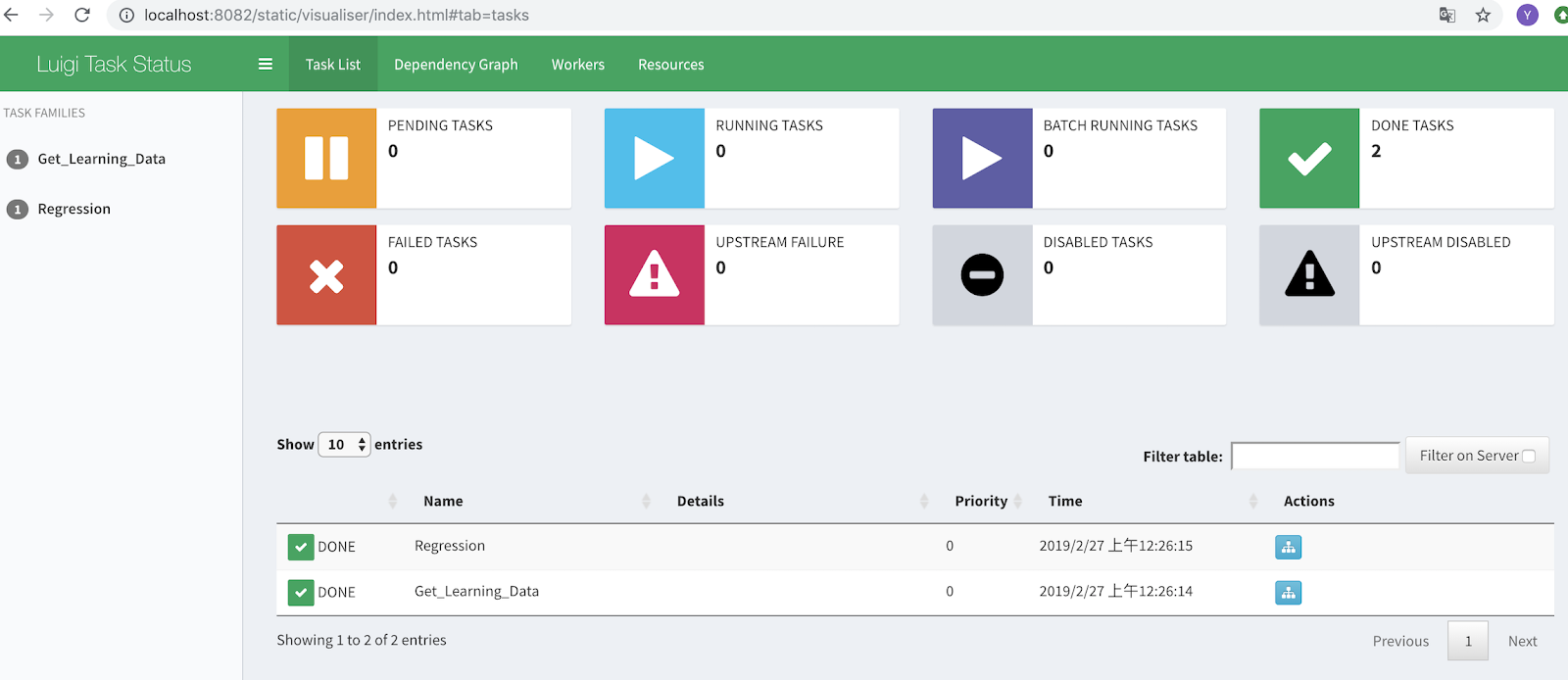
The order of the running can also be checked in the website.
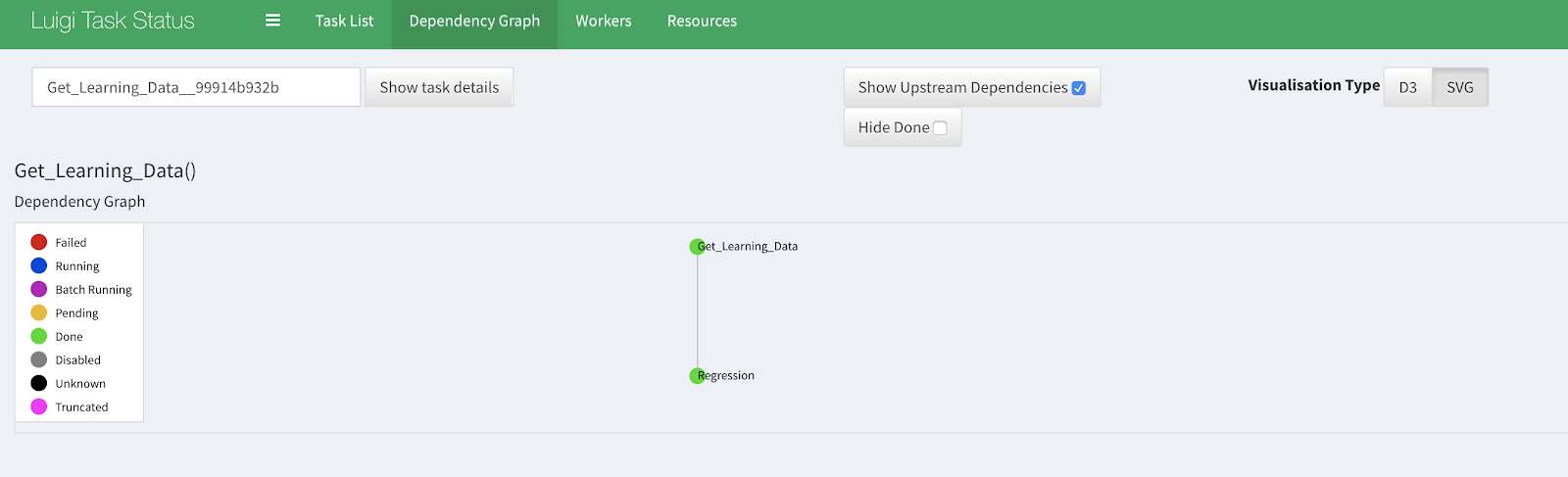
2.Dockerizing the Luigi Pipeline
After install docker package, we can build a container specific for running the pipeline application. After logging in the docker hub on the terminal and building the container, we can use "docker run --rm --link luigid pysysops/luigi-task --module Assignment2 Regression" to run the pipeline application on the container.
After the finish of both the tasks, we have to push the docker to the docker hub by using commands:
"docker tag fae247376593 shadder2k/verse_gapminder:secondtry"
"docker push shadder2k/verse_gapminder"